Siguiendo el atículo anterior sobre fundamentos de SQL Server: SQL101: Simple Recovery Model, en este vamos a tratar sobre el modelo más extendido, Full Recovery Model.
Empecemos haciendo un repaso de las principales características de este modelo de recuperación:
- Requiere hacer backups del Log de Transacciones.
- No hay perdida de datos. Esto es cierto mientras el tail log backup está disponible, en otro caso, los cambios posteriores al último backup del log de transacciones necesitan ser repetidos.
- Se puede hacer una recuperación de la base de datos al instante deseado, normalmente antes del error de aplicación o usuario que motiva la restauración. Dicho de otro modo, permite restauraciones Point-in-time.
- Permite configuraciones de Alta Disponibilidad como AlwaysOn Availability Groups y Database Mirroring. También habilita el uso de Log-Shipping, Change Data Capture,… en resumen, cualquier característica que se apoye en el uso del Transaction Log.
De lo citado anteriormente, lo más importante del Full Recovery Model es que nos posibilita el no tener pérdida de datos en caso de un desastre. Pero además de tener esta opción en nuestra base de datos, hace falta establecer un mecanismo automático de copias de seguridad que haga uso de los diferentes tipos de backups: Full, Differential (no es obligatorio pero sí recomendable), y Log.
Una estrategia sencilla de copias de seguridad puede ser la siguiente:
- Full backup: Cada semana.
- Differential backup: Cada día.
- Log backup: Cada N minutos.
De esta forma, en el caso más extremo, como máximo se perderían las acciones recientes entre el último Log backup y el momento del desastre. Si ocurrido el desastre, aún podemos acceder a la instancia de SQL Server y podemos hacer un Tail Log backup, no habrá perdida de datos alguna. Veamos un esquema a continuación:
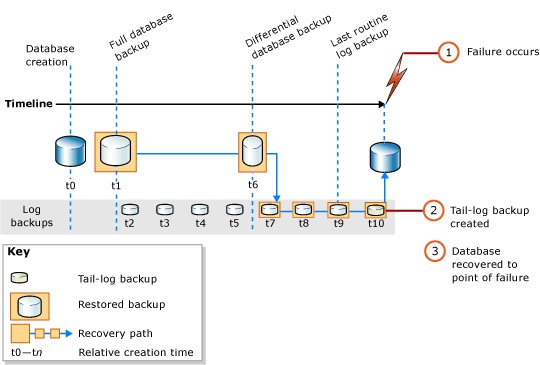
Ejemplo de escenario de desastre y pasos a realizar para evitar pérdida de datos usando Full Recovery Model. Fuente
Imaginemos una aplicación o usuario que realiza una operación como borrar/modificar por error millones de registros de una tabla crítica para el negocio. Esto puede significar un desastre para muchas empresas. Pero no nos alarmemos, tiene solución. Se puede restaurar la Base de Datos al momento anterior a que eso ocurriese, tan sólo hace falta la intervención de un operador experto (DBA) de SQL Server, y usando los backups existentes, recuperará el sistema al punto deseado, permitiendo que la aplicación vuelva a funcionar y aseguando la continuidad del negocio.
Ahora puede surgirnos una pregunta… ¿Qué debemos hacer para tener una base de datos en Full Recovery Model?
- Modificar la opción a nivel de la base de datos.
USE master; GO ALTER DATABASE [NombreDeTuDB] SET RECOVERY FULL;
- Realizar un Full backup inicial.
USE master; GO BACKUP DATABASE [NombreDeTuDB] TO DISK = '...\ruta\fullBackup_fileName.bak' WITH --...(opciones deseadas: compresion, encriptacion, etc); - Configurar una estrategia de backups (Full y Logs como mínimo). Ejemplo un job de SQL Agent, que realice las copias de seguridad según la estrategia que definamos.
- Los backups deberían estar al menos en una ubicación diferente a la máquina que ejecuta la instancia de la base de datos.
El punto 2) de esta lista es fundamental, esa copia inicial es la que inicia la cadena de backups. Sobre el punto 3) se recomienda en una ubicación diferente a la máquina de de la base de datos, por motivos de seguridad en caso de problemas que nos impidan acceder a ese servidor (inundación, fuego, virus informático, etc), además no tener una sola copia sino varias y en diferentes localizaciones.
Llegados a este punto, podemos preguntarnos qué desventaja tiene el Full Recovery Model. La mayor obligación que implica es la de tener que gestionar el Transaction Log (y sus VLFs) y hacer los Transacion Log Backups, pero siendo una tarea típicamente automatizada no debería suponer apenas esfuerzo. Otro inconveniente que podemos observar, es que hay ciertas operaciones que pueden hacer un uso muy intensivo del Transaction Log, como una carga masiva de datos desde un fichero, o una recostrucción de índices en una tabla muy grande. En esos casos, el Transaction Log debe tener el tamaño necesario para contener el detalle de estas operaciones. Otra opción posible es el uso temporal, mientras dure la operación, del tercer y último modelo de recuperación: Bulk Logged. Pero sobre esto hablaremos en un próximo artículo de fundamentos de SQL Server.
Espero que el artículo haya resultado de ayuda, como repaso de lo ya sabido o como primera toma de contacto. Como siempre…
¡Hasta la próxima!

Pingback: SQL101: Bulk-Logged Recovery Model | boni SQL
Más sobre estrategias de backups ? full vs simple, qué pasa con el log de transacciones , shrink, … ?
Me gustaMe gusta